
经典赛——乘用车销量分析
ccf bdci 乘务车——销量
近期完成了第一个数据相关的竞赛,特此记录一下。
[赛题网址](https://www.datafountain.cn/competitions/352

首先对于数据分析类的问题,想起之前打数学建模比赛,跟c题有异曲同工的意思。都是大量的数据操作。
这是大赛的数据集。
对于数据操作的基本步骤如下
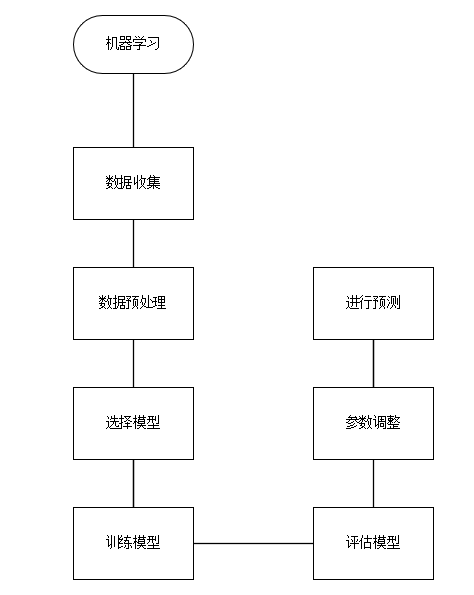
数据收集
这里主办方给了数据集,我们直接进行数据预处理,
数据预处理
经过excel简单的处理,我们发现,数据并没有缺失,所以无须担心为空白的情况。另外,我们发现model字段 一堆字符串,可以将它离散成为1,2,3 之类的代码,然后观测到,数据的最大值和最小值偏离很大,我们可以采用对数化处理
y = ln y + 1 ; 反对数化 y = e^(y-1)
这样方便处理,以及让数据呈现成正态分布。
数据预处理完成后进行特征工程
特征工程
特征工程,根据网上所查阅的资料是这样的:
特征工程是这样一个过程:将数据转换为能更好地表示潜在问题的特征,从而提高机器学习性能。特征工程就是一个把原始数据转变成特征的过程,这些特征可以很好的描述这些数据,并且利用它们建立的模型在未知数据上的表现性能可以达到最优(或者接近最佳性能)。
在数据集原来带有的特征情况下, 我们可以进行简单的加减,对比操作,来得到新的特征。
小结:特征构建比较麻烦,需要一定的经验,需要结合具体的业务,花费大量的时间去观察原始数据,思考问题的潜在形式和数据结构,以及如何将特征数据输入给预测算法。
比如在这个赛题中,我们明显可以看到,销售量伴随着时间而变化。说明销量跟季节性是相关的,我们可以简历时间序列模型,此外每个月的环比,同比也可以作为销量。然后赛题还提供了互联网搜索量,我们可以根据这些来提取有用的特征,比如说某辆车的评论,是不是代表着最近互联网讨论的人很多,然后提高该车的知名度,从而提升销售。
参考了几个大佬的做法,采用决策树模型,和时间序列模型,运用模型融合的方法,设置权重,从而提升数据的准确性。
模型选择
LightGBM(LGB)模型是一种基于梯度提升决策树(GBDT)的机器学习模型,它通过优化传统的GBDT算法,提高了训练速度、降低了内存消耗,并且能够更好地处理大规模数据集。
参考链接 lgb
1 | 1 原生模式 |
主要机器学习 就是特征工程,调参的过程。需要不断的尝试。
模型训练

我们从控制台上看到 正在训练模型。 等待几分钟训练差不多了。我们得到结果 然后去官网上交。
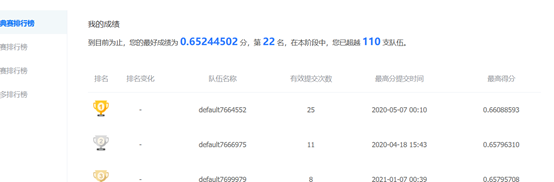
到此全部结束。




