
序章-0
前言:如何学习好一门新的学科,我觉得学习好新的知识,静下心来学习会比较好,不要畏难,而不去开始,那么你就会原地踏步。总的来说,不是选择做有意义的事情,而是做了才会有意义,相信自己,给自己正向的心理暗示。不宜妄自菲薄,引喻失义。(此外很久之前就看过了,这次再来做一个记录)。
链接
深度学习需要的能力?
| 前提假设 | 真相 |
|---|---|
| 大量专业的数学背景 | 高中知识即可 |
| 大量的数据 | 目前已知,破纪录的数据不超过50项 |
| 大量昂贵的电脑 | 可以通过各种途径去获得 |
如何学习深度学习
书中提到,教学就应该像教学生如何玩游戏一样,不要想多么花哨的技巧,首先你得先让他接触,带他们看打棒球或者让他们联系打棒球。不需要教他们的物理原理。如果死记硬背能够成功的话,那么人工智能早就可以取代我们了(有些是我本人的观点)。通过死记硬背的方式会导致学生早早放弃了学习教学。记住一点,无需仰望他人,你亦是自己的光,即使没有非常专业的学术背景,你也可以学好深度学习。马斯克曾经说过:一个优秀的人才需要深刻理解人工智能,并有实打实的能力来运用人工智能,一个人有实力,不会在乎他的学历背景。
可能用到的库、环境? pytorch fastai jupyter
其实用什么库并不需要,从一个库切换到另一个库只需要几天时间去学习就好了。对我们来说,真正重要的是打好深度学习的基础、学好想概念的技术,对于某些概念,最好能够清晰的使用代码去实现,高层概念,可以使用fastai解释,底层概念会用pytorch 或者python代码去实现。(坚持真的很难,他不一定成功,但不坚持必定失败,不要在意他人的眼光,做你自己即可,特别喜欢一句话,悟已往之不谏,知来者之可追,实迷途其未远,觉今是而昨非,不管怎么样,做就完事了)。
他提供的网站:jupyter notebook:这款软件可以让你在单个交互文档中编辑带格式的文本、代码、图像和视频等等。根据他的提示,可以使用它提供的notebook来训练猫和狗的模型,而无需我们下载,非常方便,就是可能有点慢,不过比自己配置文件好很多。
运行第一个notebook
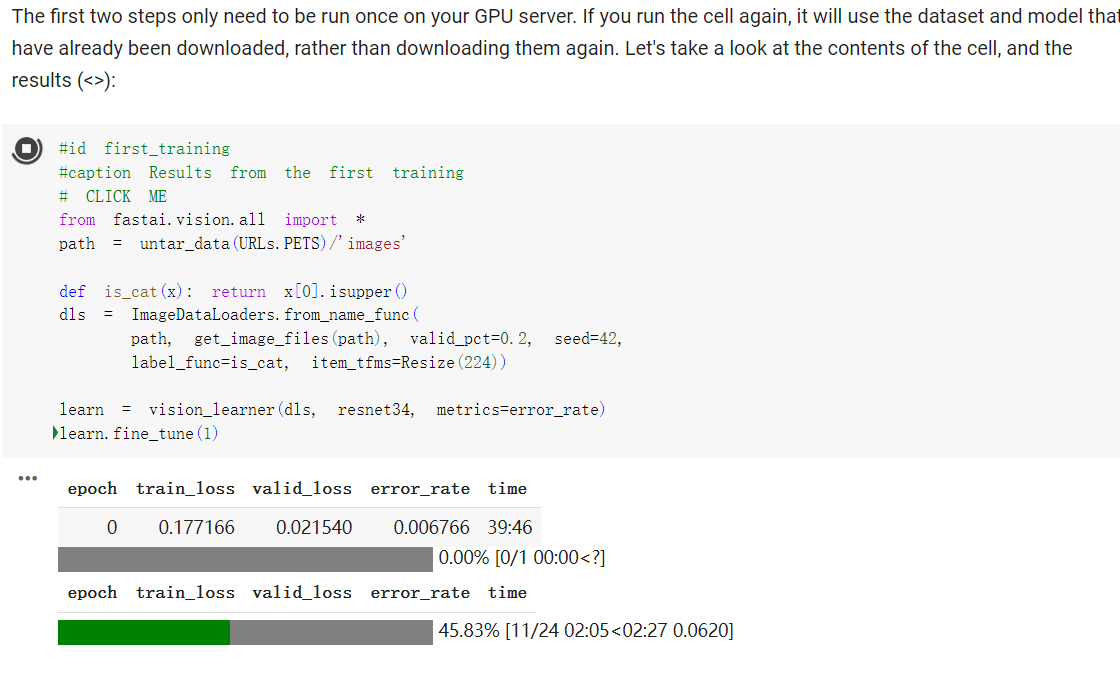
如书上所说:这个notebool 会下载一个数据集,还会下一个预训练模型:之后会使用迁移学习中相关技术对预训练模型进行微调,从而创建识别任务的资质模型。
跑了一小时终于跑出来了
什么是机器学习
深度学习中神经网络最早可追溯到20世纪50年代。
机器学习:是一种能使计算机完成某项特定任务的方式
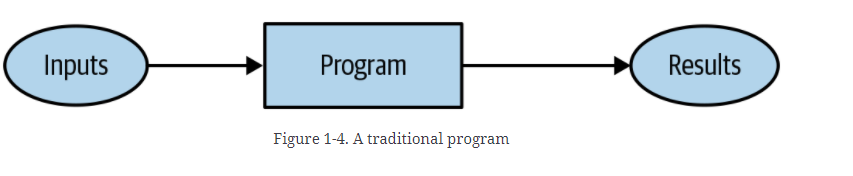
机器学习不应该告诉计算机解决问题的具体步骤,而是向计算机展示各种问题的案例,然后让计算机自行得出解决问题的最佳问题。给各个步骤分配权重,让性能最优。
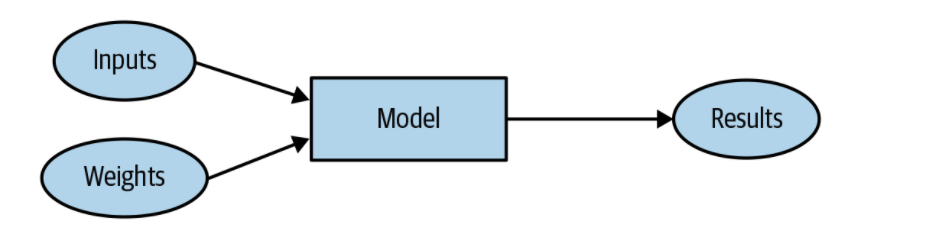
将程序转换为模型,指出模型是一种特殊的程序。所以不同权重值将得出不同的跳棋策略。权重称之为模型参数。
当然我们需要一种机制可以改变权重分配,让机器自行调整全懂实现全自动。
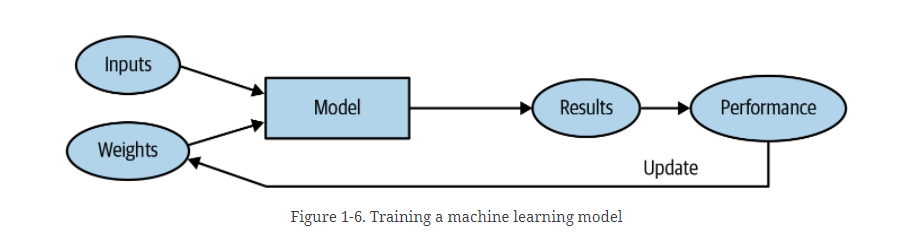
在经过多次训练后,那么模型最终会成为被分配好的最终的,最好的,最喜欢的权重,不需要区分模型的输出结果和模型的性能,可以吧权重当作模型的一部分,最终模型如下图所示。

总结:机器学习是指计算机从经验中学习而非通过人工对各个步骤变成来训练程序。
什么是神经网络
简单概括就是:神经网络是一种特定的机器学习模型。神经网络的特殊之处就是在于它具有高度的灵活性,只要我们找到合理的权重,神经网络就可以解决很多问题,而随机梯度下降为我们提供了一种可以自动找到这些权重的方法,这是非常强大的。
一些深度学习的术语
模型:(model)的功能形式被称为架构。但是两者并不能混为一谈。
权重:(weight)可以被成为参数。
自变量:(independent variable)计算得出预测,预测包含数据,不包括标签
结果:result 可以被称为预测
模型的性能:评估结果可以被称为损失(loss)
损失不仅仅取决于预测,也和正确的标签高度相关,也常称为标签为目标或因变量。比如说猫狗就是标签。相应的图如下。
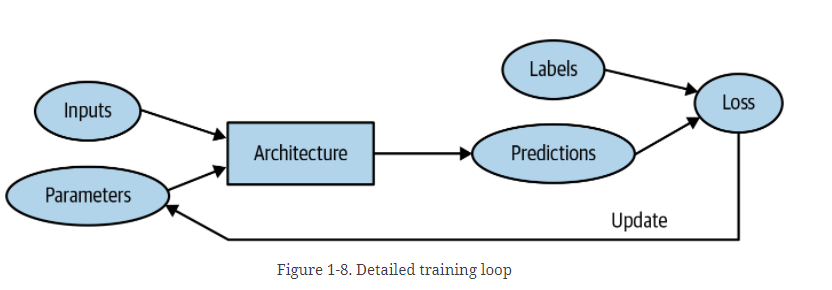
机器学习的局限性
- 没有数据无法创建出一个模型
- 模型只能学习处理用于训练模型的输入数据中所存在的模式
- 这种学习方法仅能给出对某一个问题的预测,但是并不能直接得出最终的决策
- 仅有输入数据的案例是不够的,我们需要给他打上标签。 比如说识别猫狗图像,我们光给图像是不行的,需要给他们打上标签,告诉他们哪些是狗,哪些是猫。
图像识别器
分类和回归的概念
分类和回归:定义很明确,分类是一种试图预测类别的模型,比如说他是狗还是猫,回归指的是一种预测一个或多个数值的模型,比如说温度或者位置。
对于 一个数据集,我们可能只拿一部分用来训练,一部分来来验证。比如说80%用来训练模型,20%用来验证模型。因为如果花大量时间训练一个模型,如果他最终记住的全是数据中的标签,那么将完全没有意义,我们应该输入他没有经过训练的数据集,来判断模型的准确率。
过拟合:
模型在训练的时间越长,准确率也就越高,但是模型会记忆训练集,而不是寻找通用的底层模式,因此最终的结果会变得糟糕。出现这种情况,我们称之为过拟合。
如何避免过拟合?之后将会介绍到。
总结:每个模型都会从选择架构开始,架构是一种描述模型内部运作方式的通用模板。训练(拟合)模型的过程 都是找到一组参数值,将通用的模型架构转变成某些特定类型的数据上进行预测或者分类的决策模型。要定义一个模型在单一预测上的表现,需要一个损失函数来对结果进行评估。
为了使训练过程进行更快,可以先使用一个预训练模型,(别人用数据已经训练好的模型) 可以使用数据继续训练他,使这个训练模型适应我们的数据,这样的过程称为微调(fine-tuning)
训练一个模型时,我们需要模型能够泛化,具有泛化性质,泛化性指的是我们用数据进行模型训练,学习到了一些通用的特征,这些特征也适用于其他的新类别,因此模型也可以对这些新类别做出良好的预测。但是训练也存在风险,学习不到通用的特征,只是记住训练过程中所见到的内容,那么就会导致模型对新图像做出糟糕的预测,这种现象称为过拟合(overfitting)。
避免:为了出现这种情况,我们需要将数据分为训练集和验证集两部分。在训练模型的时候使用训练集,然后根据模型在验证集上的表现用来评估模型的好坏。通过这种方式,检查模型从训练集学到的通用特性是否适用于验证集。为了评估验证集上的整体表现,我们定义了一个指标(metric)。在训练过程中,当模型在训练过程中看过了训练集中的每一个数据,我们就把这个过程称为训练完了一轮或者一个周期(epoch)
最后:还是有很多概念的,需要细细理解






